
From left to right: Huang Zhiying, Wang Zixiao, Zhang Yu, Yu Hui, Wu Yiyang
The graph computing team from the School of Computer Science and Technology, led by Associate Professor Zhang Yu, recently broke two world records of Open Graph Benchmark (OGB) 2022, with their novel graph learning model GIDN developed on the self-developed graph computing platform. The model broke both world records in link property prediction and ranked top globally on predicting drug-drug interactions and future author collaboration relationships, with accuracy of 0.9542 and 0.7096 respectively.
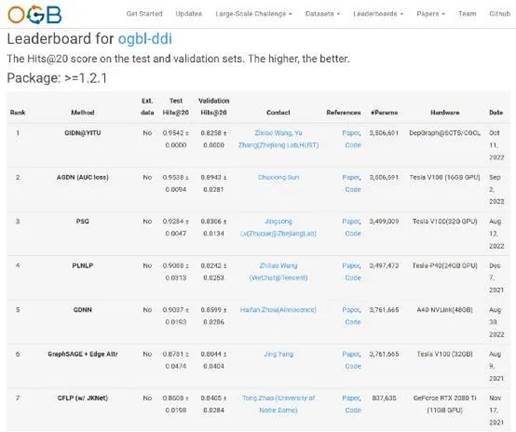
Drug-drug Interactions Prediction Accuracy Ranks No.1
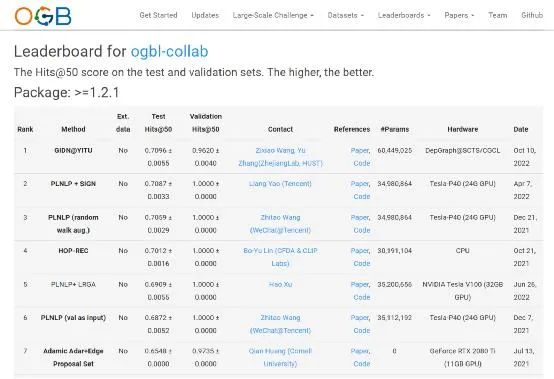
Author Collaboration Relationships Prediction Accuracy Ranks No.1
GIDN was completed by the group of Wang Zixiao, Guo Yuluo, Huang Zhiying, Yu Hui, and Wu Yiyang, led by Wang Zixiao.
The OGB, a collection of realistic, large-scale, and diverse benchmark datasets for machine learning on graphs, was established by top-tier scholars in graph learning, aiming at comparing front-edge graph learning models.
The OGB provides a diverse set of challenging and realistic benchmark datasets for a variety of graph machine learning tasks, including the prediction of node, link, and graph properties. For example, the datasets ogbl-ddi and ogbl-collab are originated from FDA-approved or experimental drug data, and Microsoft Academic Graph respectively.
GIDN can accurately predict whether there is any correlation between two original irrelative things, it could be utilized to predict drug-drug interactions and future author collaboration relationships. The ogbl-ddi dataset contains 4267 drug data and over 100 types of drug interactions. GIDN can input interaction data to the graph learning model and predict drugs with combinational effects accurately, which reduces clinical validation time and R&D costs in drug research. The ogbl-collab dataset contains more than 200,000 authors, and 1.2 million partnership data. Given the information in the dataset, GIDN could predict future author collaboration relationships accurately, allowing administrative staff to improve management efficiency, and researchers to determine an appropriate collaborator.
The representation of relationships between objects through graphs can be used in many scenarios in real life. As one of the key technologies in big data processing and artificial intelligence, graph learning can obtain abundant information behind complicated graph data, which shows enormous potential in health care, finance, education, military, scientific discovery, and other fields, like drugs and virus interaction prediction, molecular properties prediction, protein structure prediction, and financial anti-fraud. The sector is vital for stimulating the nation's digital transformation, intelligent upgrading, and integrated innovation, and will become a leading strategic position in the global technology competition.
Written by: Wang Yijie
Edited by: Peng Yumeng

 Chinese
Chinese



