A few months ago, cutting-edge technology from HUST enabled “little monkey”, an AI system, to describe pictures. Recently, the "little monkey" AI has been upgraded. In joint efforts with Kingsoft Office, HUST presented the large multimodal model TextMonkey, taking an international lead on multiple document comprehension and solidly stepping toward universal character recognition.
At the end of last year, the large multimodal model Monkey-chat was released by the VLRLab team, led by Prof. Bai Xiang from the School of Software Engineering. The model can observe environments, engage in detailed Q&A sessions and provide accurate descriptions of images.
It is reported that large multimodal models are able to simultaneously process and integrate multiple perceptual data, performing exceptionally in a variety of scenarios. With its remarkable world knowledge and extraordinary discourse abilities, multi-modal large language models can deeply comprehend and sense the world like human beings.
Recently, the premier international conference for artificial intelligence, CVPR 2024, accepted the Monkey-chat large multimodal model. Monkey-chat also ranked highly on the OpenCompass multi-modal leaderboard, trailing only a few spots behind industry leaders like OpenAI's GPT4V, Google's Gemini and other closed-source models.
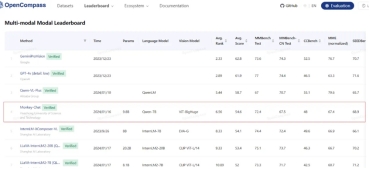
With its breakthroughs in 12 document authority datasets, including OCRBench, and the most comprehensive intelligent dataset of document images in the world, TextMonkey represents a significant upgrade to Monkey in the document field. Its performance in document understanding significantly surpasses that of current methods.
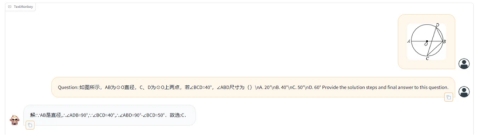
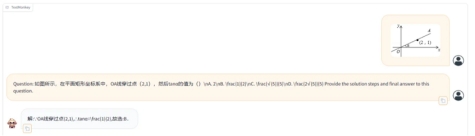
TextMonkey can help us solve math problems with step-by-step solutions, which is helpful to the automation of education.
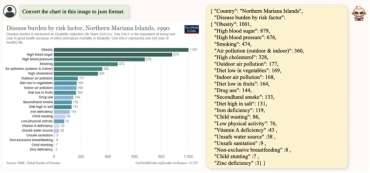
TextMonkey automatically structures charts into json format
TextMonkey can help users better understand structured charts, tables and document data. It makes recording and extraction easier by converting graphical content into a lightweight data exchange format.
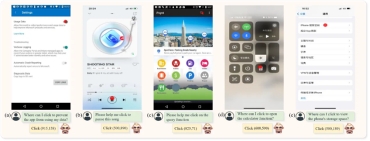
TextMonkey acts as a smartphone agent to control mobile apps
Additionally, TextMonkey can serve as a smartphone assistant. Without interaction with the back end, it can process various tasks on a mobile device and autonomously operate applications with just voice input and a snapshot of the screen.
The core of TextMonkey is its capacity to imitate human visual cognition methods. This allows it to intuitively identify key elements and recognize the connections between different parts of a high-definition document image. Furthermore, based on the thorough understanding of the diverse needs of users, TextMonkey improves its accuracy by text localization techniques effectively. After enhancing the explanatory nature of its model, it significantly promotes its multitasking capabilities.
Currently, with the speeding digital transformation, multi-modal structured analysis and information extraction of documents and images are becoming increasingly important. Quick, automated and accurate data processing is critical in increasing industrial productive efficiency. In this context, the introduction of TextMonkey offers a creative and all-encompassing solution to this challenge. Hopefully, it can take the lead in accomplishing technological breakthroughs in the fields of office automation, intelligent education and intelligent finance, lighting the way forward in comprehensively upgrading universal document understanding.
Written by: Fang Siyuan
Edited by: Yang Kunjie, Chang Wen, Peng Yumeng

 Chinese
Chinese



